Вступление.
Прежде всего стоит сказать, что такое Код Хэмминга и для чего он, собственно, нужен. На Википедии даётся следующее определение:
Другими словами, это алгоритм, который позволяет закодировать какое-либо информационное сообщение определённым образом и после передачи (например по сети) определить появилась ли какая-то ошибка в этом сообщении (к примеру из-за помех) и, при возможности, восстановить это сообщение. Сегодня, я опишу самый простой алгоритм Хемминга, который может исправлять лишь одну ошибку.
Также стоит отметить, что существуют более совершенные модификации данного алгоритма, которые позволяют обнаруживать (и если возможно исправлять) большее количество ошибок.
Сразу стоит сказать, что Код Хэмминга состоит из двух частей. Первая часть кодирует исходное сообщение, вставляя в него в определённых местах контрольные биты (вычисленные особым образом). Вторая часть получает входящее сообщение и заново вычисляет контрольные биты (по тому же алгоритму, что и первая часть). Если все вновь вычисленные контрольные биты совпадают с полученными, то сообщение получено без ошибок. В противном случае, выводится сообщение об ошибке и при возможности ошибка исправляется.
Как это работает.
Для того, чтобы понять работу данного алгоритма, рассмотрим пример.
Подготовка
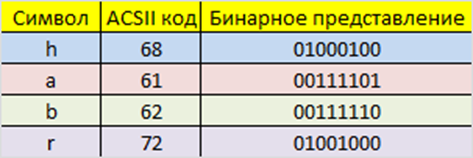
Допустим, у нас есть сообщение «habr», которое необходимо передать без ошибок. Для этого сначала нужно наше сообщение закодировать при помощи Кода Хэмминга. Нам необходимо представить его в бинарном виде.

На этом этапе стоит определиться с, так называемой, длиной информационного слова, то есть длиной строки из нулей и единиц, которые мы будем кодировать. Допустим, у нас длина слова будет равна 16. Таким образом, нам необходимо разделить наше исходное сообщение («habr») на блоки по 16 бит, которые мы будем потом кодировать отдельно друг от друга. Так как один символ занимает в памяти 8 бит, то в одно кодируемое слово помещается ровно два ASCII символа. Итак, мы получили две бинарные строки по 16 бит:
 и
и
После этого процесс кодирования распараллеливается, и две части сообщения («ha» и «br») кодируются независимо друг от друга. Рассмотрим, как это делается на примере первой части.
Прежде всего, необходимо вставить контрольные биты. Они вставляются в строго определённых местах — это позиции с номерами, равными степеням двойки. В нашем случае (при длине информационного слова в 16 бит) это будут позиции 1, 2, 4, 8, 16. Соответственно, у нас получилось 5 контрольных бит (выделены красным цветом):
Было:
Стало: 
Таким образом, длина всего сообщения увеличилась на 5 бит. До вычисления самих контрольных бит, мы присвоили им значение «0».
Вычисление контрольных бит.
Теперь необходимо вычислить значение каждого контрольного бита. Значение каждого контрольного бита зависит от значений информационных бит (как неожиданно), но не от всех, а только от тех, которые этот контрольных бит контролирует. Для того, чтобы понять, за какие биты отвечает каждых контрольный бит необходимо понять очень простую закономерность: контрольный бит с номером N контролирует все последующие N бит через каждые N бит, начиная с позиции N. Не очень понятно, но по картинке, думаю, станет яснее: 
Здесь знаком «X» обозначены те биты, которые контролирует контрольный бит, номер которого справа. То есть, к примеру, бит номер 12 контролируется битами с номерами 4 и 8. Ясно, что чтобы узнать какими битами контролируется бит с номером N надо просто разложить N по степеням двойки.
Но как же вычислить значение каждого контрольного бита? Делается это очень просто: берём каждый контрольный бит и смотрим сколько среди контролируемых им битов единиц, получаем некоторое целое число и, если оно чётное, то ставим ноль, в противном случае ставим единицу. Вот и всё! Можно конечно и наоборот, если число чётное, то ставим единицу, в противном случае, ставим 0. Главное, чтобы в «кодирующей» и «декодирующей» частях алгоритм был одинаков. (Мы будем применять первый вариант).
Высчитав контрольные биты для нашего информационного слова получаем следующее: 
и для второй части: 
Вот и всё! Первая часть алгоритма завершена.
Декодирование и исправление ошибок.
Теперь, допустим, мы получили закодированное первой частью алгоритма сообщение, но оно пришло к нас с ошибкой. К примеру мы получили такое (11-ый бит передался неправильно):
Вся вторая часть алгоритма заключается в том, что необходимо заново вычислить все контрольные биты (так же как и в первой части) и сравнить их с контрольными битами, которые мы получили. Так, посчитав контрольные биты с неправильным 11-ым битом мы получим такую картину: 
Как мы видим, контрольные биты под номерами: 1, 2, 8 не совпадают с такими же контрольными битами, которые мы получили. Теперь просто сложив номера позиций неправильных контрольных бит (1 + 2 + 8 = 11) мы получаем позицию ошибочного бита. Теперь просто инвертировав его и отбросив контрольные биты, мы получим исходное сообщение в первозданном виде! Абсолютно аналогично поступаем со второй частью сообщения.
Заключение.
В данном примере, я взял длину информационного сообщения именно 16 бит, так как мне кажется, что она наиболее оптимальная для рассмотрения примера (не слишком длинная и не слишком короткая), но конечно же длину можно взять любую. Только стоит учитывать, что в данной простой версии алгоритма на одно информационное слово можно исправить только одну ошибку.
Примечание.
На написание этого топика меня подвигло то, что в поиске я не нашёл на Хабре статей на эту тему (чему я был крайне удивлён). Поэтому я решил отчасти исправить эту ситуацию и максимально подробно показать как этот алгоритм работает. Я намеренно не приводил ни одной формулы, дабы попытаться своими словами донести процесс работы алгоритма на примере.
Код Хэмминга: алгоритм
Код Хэмминга — это один из первых кодов, позволяющих обнаруживать и корректировать возникающие случайные ошибки.
Введение
Системы кодирования, являющиеся средствами тайнописи, появились ещё в древние времена. Древнегреческий учёный Геродот ещё в пятом веке до нашей эры сообщал о методиках написания писем, которые сможет понять только адресат письма. При трансляции данных по информационным каналам также начали применяться различные системы кодирования и в числе первых стоит кодовая система Самуэля Морзе. В его системе точек и тире было разное количество знаков для кодирования числовой и символьной информации.
Коды, содержащие пару различных несложных сигнала, называются двоичными или бинарными. Эти сигналы, как правило, отображаются при помощи цифр единица и нуль. То есть всё закодированное сообщение состоит из последовательности единиц и нулей.
Готовые работы на аналогичную тему
Различные алгоритмы выполнения арифметических операций способны выдать правильный результат лишь тогда, когда не наблюдается различного рода сбоев в работе технических устройств. При возникновении каких-либо отклонений в правильном функционировании кодового оборудования, результирующий итог может оказаться неверным, но получатели информации могут и не подозревать об этом, если нет способов, способных обнаружить и сообщить об ошибках. То есть, создатели алгоритмов кодировки данных, должны предусматривать способы, позволяющие корректировать возникающие ошибки.
Код Хэмминга
Система кодирования Хэмминга является самой известной и одной из первых систем, которые способны сами себя контролировать на наличие ошибок и даже эти ошибки исправлять. Базируется эта система на бинарной системе счисления. То есть, эта система является алгоритмом, позволяющим выполнить кодирование какого-то информационного сообщения некоторым способом и отправить его адресату. На принимающей стороне имеется возможность обнаружить возникшие при трансляции сообщения ошибки и, если это возможно, ликвидировать все ошибки. Следует заметить, что есть простой алгоритм способный, справиться с одной ошибкой, но есть и улучшенные версии этого алгоритма, которые дают возможность найти и, если есть возможность, ликвидировать много возникших ошибок.
Отметим также, что система кодирования Хэмминга имеет две составные части. В первой части выполняется кодирование исходной информации, причём в процессе кодирования осуществляются вставки в сообщение в заданных точках контрольных битов, вычисленных по специальным выражениям. Во второй части выполняется приём передаваемого сообщения и повторное вычисление контрольных битов. Алгоритм вычислений такой же, как и в первой части. В случае, когда найденные контрольные биты равняются полученным в сообщении, то значит передаваемое сообщение принято безошибочно. Если же имеются несовпадения в контрольных битах, то идёт сообщение об ошибке и далее, если это возможно, ошибочные данные корректируются.
Для иллюстрации действия того алгоритма, приведём конкретный пример. Предположим, имеется информация «habr», которую требуется отправить с условием, что получатель её увидит точно в таком же виде, то есть без ошибок. С этой целью, сначала необходимо выполнить кодирование сообщения при посредстве системы Хэмминга. Поэтому выполним перевод сообщения в двоичный код:

Рисунок 1. Перевод сообщения в двоичный код. Автор24 — интернет-биржа студенческих работ
Теперь нужно определить допустимую длину единицы передаваемой информации, то есть это длина строки, состоящей из нулей и единиц, которую можно кодировать и передавать за один раз. Выберем длину слова равной шестнадцати. Тогда требуется выполнить разделение всего исходного сообщения на участки по шестнадцать бит, которые будут подвергаться кодированию независимо друг от друга. Поскольку код одного символа равняется восьми битам, то, следовательно, в одном кодируемом слове будет точно две буквы. В итоге получаем две строки по шестнадцать бит в двоичном коде:

Рисунок 2. Строка кода. Автор24 — интернет-биржа студенческих работ

Рисунок 3. Строка кода. Автор24 — интернет-биржа студенческих работ
Далее кодирование выполняется отдельно для каждой части. Приведём в качестве примера кодирование первой части. Как указывалось выше, нужно выполнить вставку контрольных битов в сообщение. Вставка выполняется в чётко заданных местах, а конкретно, это позиции с нумерацией, определяемой степенями основания системы счисления, то есть цифры два. Для нашего примера эти позиции равны 1, 2, 4, 8, 16. Таким образом, получаем пять контрольных бит, которые на рисунке ниже выделяются красным:

Рисунок 4. Строка кода. Автор24 — интернет-биржа студенческих работ
Отметим, что размер сообщения вырос на пять бит, но ещё необходимо вычислить значения контрольных битов, которые пока обозначены нулями. Величина всех контрольных битов имеет зависимость от величин информационных разрядов, только не от всех подряд, а только от контролируемых данным битом. Правило здесь следующее, контрольный бит, имеющий номер N, отвечает за контроль всех последующих N битов через каждые N. Отсчёт начинается именно с позиции N. Проиллюстрируем это правило изображением ниже:

Рисунок 5. Таблица. Автор24 — интернет-биржа студенческих работ
На этом рисунке символом «Х» обозначаются биты, контролируемые контрольным битом, а его номер находится правее. Например, бит, имеющий номер двенадцать, находится под контролем битов, имеющих номера четыре и восемь. Вычисление значения контрольного бита осуществляется следующим образом, для каждого контрольного бита определяется количество единиц в наборе контролируемых им битов, и если это число чётное, то контрольный бит равен нулю, если нечётное, то он равен единице. После вычислений всех контрольных битов для рассматриваемого примера, получаем следующий код для первой части сообщения:

Рисунок 6. Строка кода. Автор24 — интернет-биржа студенческих работ
Для оставшейся части:

Рисунок 7. Строка кода. Автор24 — интернет-биржа студенческих работ
Во второй части алгоритма выполняется повторное вычисление всех контрольных битов, и они сравниваются с полученными в сообщении битами. Предположим, что после вычислений контрольных битов обнаружен неверный одиннадцатый бит, что даст следующее:

Рисунок 8. Строка кода. Автор24 — интернет-биржа студенческих работ
Как видно, контрольные биты, имеющие номера 1, 2, 8 не равны контрольным битам, вычисленным после получения сообщения. Тогда просто выполнив сложение номеров позиций неверных контрольных битов, вычисляем позицию неверного бита. То есть 1 + 2 + 8 = 11, и осталось просто выполнить его инверсию, убрать биты контроля, после чего получается исходное сообщение без ошибок. Таким же образом декодируется и вторая часть сообщения.
https://habr. com/ru/post/140611/
https://spravochnick. ru/informatika/kod_hemminga_algoritm/